




Blog
PRIME-1: Scaling Large Robot Data for Industrial Reliability

Written by Vishal Satish, Jeff Mahler, and Ken Goldberg
Since 2018, Ambi Robotics has pioneered simulation-to-reality AI, enabling us to rapidly train robots to grasp a huge variety of items without tedious real-world data collection. This advance led to swift commercialization, with Ambi deploying over 80 AmbiSort A-Series AI-powered robotic machines to sort packages for ecommerce shippers.
Since then, as our robots operated across the US supporting ecommerce, we have closely tracked progress in AI. ChatGPT and related “foundation” models have shown that AI transformer models pre-trained on massive amounts of unlabeled data with unsupervised learning can vastly outperform models trained on only labeled data in domains such as language modeling (LLMs) and image understanding (VLMs).
The success of these efforts has led to a surge of interest in robot foundation models: general AI models that perform a wide variety of tasks in the physical world. Initial experiments with data gathered from human tele-operation[1][2] show promise, demonstrating robots performing a diversity of tasks such as folding laundry and operating a toaster, with a single model. However, published success rates are well short of the reliability required for industrial automation tasks.
This raises a key question: how does the reliability of a foundation model scale as a function of pre-training data for a specific industrial domain?
After several years of operation, our fleet of Ambi robots has collected a scale of data far beyond the amount used for our original system. So far, we have collected over 200k operational hours of high-fidelity, focused data from processing real parcels for customers in production environments, corresponding to well over 1 billion images from individual pick and place events. This provides a critical mass of high-quality data for creating highly reliable and data-driven foundational AI models, putting us in prime position to study AI scaling laws in industry.
The PRIME-1 Model
In our recent Jan 7th press release, we announced PRIME-1 (“Production-Ready Industrial Manipulation Expert”), a generative AI model for warehouse robots. PRIME-1 is a domain expert foundation model pre-trained in a self-supervised fashion on over 20 million images from production robot operations to learn 3D reasoning that is applicable to downstream tasks in perception, picking, placement, and quality control. PRIME-1 allows us to polish the performance of AmbiSort package sorting systems and provides the basis for Ambi to develop new package handling systems such as AmbiStack.
Below, we explore how the reliability of PRIME-1 on downstream tasks scales as a function of data by pre-training on increasing orders of magnitudes of unlabeled data collected from commercial operations. We apply the model to the downstream tasks of stereo vision and pick planning and find empirical evidence of scaling laws in these tasks.
Industrial-Grade Reliability in 3D Applications
PRIME-1 is trained in two stages: pre-training and fine-tuning (or post-training). In pre-training, the model is trained to reconstruct image data between camera viewpoints from unlabeled data collected in production. So far, we’ve used 10M camera image pairs – or 20M unique images – for pre-training. In post-training, the model is fine-tuned to the applications of interest to a high degree of reliability on two challenging 3D tasks: stereo vision and pick planning.
The goal of stereo vision is to estimate 3D geometry based on a pair of 2D camera images. This typically works by finding corresponding points between the left and right images and using this information to triangulate the distance of an item from the camera in 3D space. This is challenging because of the sensitivity of the task to correspondence errors, where small differences in pixel space translate to large errors in 3D, and the difficulty of matching corresponding points in each image, especially when there is low color variation or occlusions. Precise downstream control often requires superhuman sub-pixel accuracy.
We fine-tune PRIME-1 for the stereo vision task using supervised learning. We evaluated on a held-out set of test images, where ground truth is established by a high accuracy 3D laser scanner, and measured performance using the L1 disparity error (average absolute disparity error). The fine-tuned model achieves a 19% reduction in error compared to our previous best-performing model, which had been operating in production for over six months.
We also used the stereo vision task to explore the utility of pre-training on in-domain data collected from Ambi production robots. Specifically, we compared with pre-training on out-of-domain data from the open source Middlebury[3], ETH3D[4], and CREStereo[5] datasets. We observed a 23% increase in test error when pre-training on open-source, out-of-domain data, suggesting that in-domain data is important for achieving high performance.

The second task we study is robotic picking, in which a robot estimates grasp affordances, or regions in 3D space that are favorable for robustly picking up a single item using suction cups. This is similar to the way a person might recognize a handle on a mug: the handle appears different on different mugs but we can always recognize it as a place we can grasp. Pick planning is difficult due to the huge variety of items, imprecision in sensing and control, and clutter that makes it difficult to see all parts of the item at once.
We fine-tune PRIME-1 for the picking task using supervised learning. We evaluate on a set of validation images, measuring performance by the average error between the predicted and actual probability of success for a grasp. We find that PRIME-1 achieves a 16% reduction in error compared to our previous best-performing model, which had been operating in production for three months.
Overall, our results suggest that the task-agnostic architecture of PRIME-1 with fine-tuning can outperform highly-reliable task-specific models.
Scaling Laws
Recent work in training foundation models has placed an emphasis on identifying “scaling laws”, i.e. power laws between system performance and the amount of training data used. A limiting factor has been the immense resources required to train on ever increasing data sizes, but this is being addressed by recent advances in large model training[6][7] by the broader AI community towards training GPT-scale models.
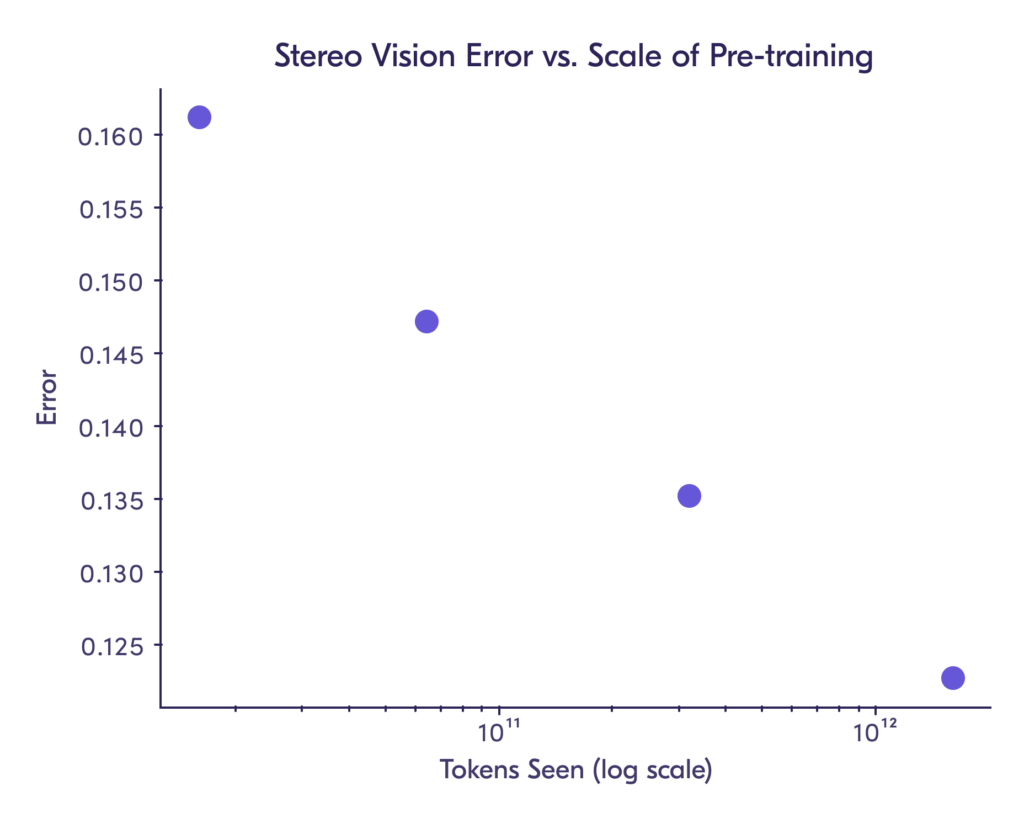
In experiments with PRIME-1 so far, we observe a similar scaling effect. More specifically, Figure 1 shows that increasing pre-training data size results in reduced error for the stereo vision task. We trained the model on increasing orders of magnitude of pre-training tokens, where a “token” is a 16×16 image patch akin to a word in the language domain.
We have not yet observed a significant saturation in performance. We have only used approximately 10% of the real data we collected for the stereo vision and picking tasks. The current limitations are cost and compute, and we plan to continue to scale up training in future work to further explore these trends.
The Scale of PRIME-1 Data
To put the scale of PRIME-1’s vast pre-training dataset in context, we provide a comparison with other significant real-world datasets in the field of embodied AI. While the tasks and data are very different, we note that PRIME-1 is already trained on a comparable scale of real-world data to other state-of-the-art models, and there is an opportunity to grow this by another order of magnitude.
|
Existing Real Robot Datasets |
Hours of Training Data |
Notes |
|
100 |
Sampled from thousands of hours of internal data |
|
|
350 |
||
|
630 |
Assuming an avg. 9 sec cycle time per “pick-and-place” |
|
|
4,000 |
||
|
10,000 |
||
|
Ambi PRIME-1 |
20,000 |
|
|
Ambi Total Production Data |
200,000 |
Total production data as of January 2025 |
Conclusion
PRIME-1 has greatly exceeded our expectations and we have the data to further improve its reliability. We also plan to expand PRIME-1 to different tasks such as item placement and quality control, and to apply it to our next generation of robot logistics systems.
There is a huge market opportunity for robotic foundation models with industrial-grade reliability that can facilitate efficient and accurate item handling in logistics, manufacturing, and beyond. PRIME-1 is an important first step in this direction.
References
[1] https://www.physicalintelligence.company/download/pi0.pdf
[2] https://robotics-fm-survey.github.io/
[3] https://vision.middlebury.edu/stereo/data/
[4] https://www.eth3d.net/overview
[5] https://github.com/megvii-research/CREStereo
[6] https://arxiv.org/pdf/2304.03589
[7] https://github.com/skypilot-org/skypilot


